Nowadays, many technical documents are delivered in PDF format.
When figures within a technical document contain text, such as user interface instructions, enabling OCR processing allows LLM to decipher the information hidden in the image, making its responses more appropriate and accurate.

But how do we confirm that LLM has correctly enabled OCR processing?
There are currently two methods.
The first one is to check with your browser’s developer tools.
After uploading the technical file, use the Preview feature and verify directly from the API that the payload parameter (ocr_enabled) is true or false.

The second is to use the Retrieval Testing feature in the Knowledge Base to directly confirm that LLM can return the correct information about the figure.
With OCR processing enabled.
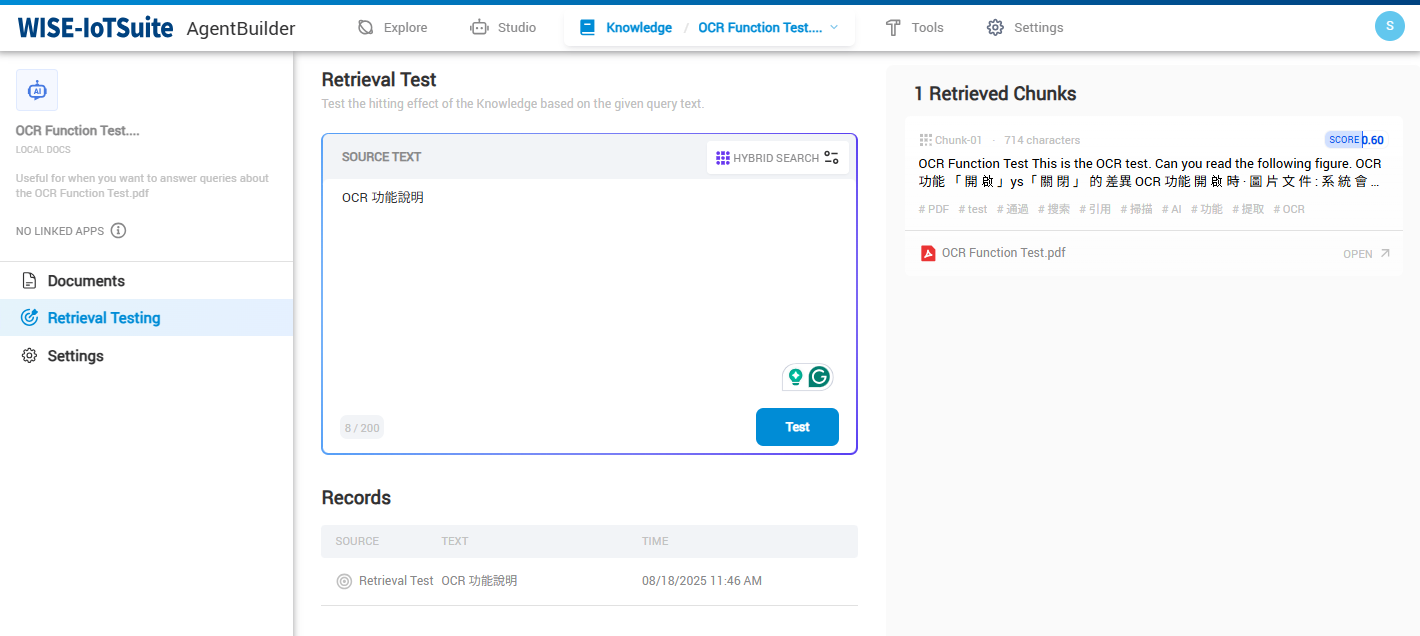
OCR processing disabled.

Hope this sharing can help you.
See you next time.